看到项目代码里的构造函数,有时候用explicit,有时候不用,引发了我的思考,到底这个关键字什么时候用呢?
带着这个问题,我查看了一些资料。
比较官方的解释是:
explicit关键字用于禁止构造函数的隐式类型转换 。
当构造函数被标记为explicit时,编译器不会自动使用该构造函数进行隐式转换。
听得似懂非懂。
还是找些具体的例子看看来说吧。
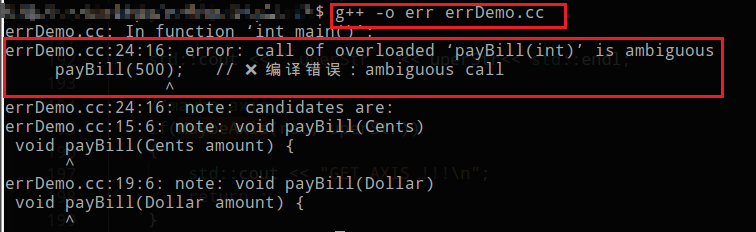
没有explicit导致的重载决议歧义错误 C++ 有一个默认特性:如果一个构造函数只接受一个参数,编译器会默认认为它定义了一种“隐式转换路径”。
在这个例子里,由于单参数构造函数没有explicit,所以没有禁止隐式转换,导致重载决议歧义错误,出现编译错误。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> class Cents { int cents_; public : Cents (int c) : cents_ (c) { std::cout << "Cents: " << c << "\n" ; } }; class Dollar { int dollar_; public : Dollar (int c) : dollar_ (c) { std::cout << "Dollar: " << c << "\n" ; } }; void payBill (Cents amount) std::cout << "Paying with cents\n" ; } void payBill (Dollar amount) std::cout << "Paying with dollars\n" ; } int main () payBill (500 ); return 0 ; }
由于两个函数的匹配程度完全相同,都需要一次用户定义的隐式转换, 编译器无法确定选择哪一个,导致编译错误
这时,我们通过使用 explicit,要求必须明确意图的进行调用,于是修改上面的代码
1 2 3 4 5 6 7 8 9 10 explicit Cents (int c) : cents_(c) {"Cents: " << c << "\n" ; } explicit Dollar (int c) : dollar_(c) {"Dollar: " << c << "\n" ; } payBill (Cents (500 )); payBill (Dollar (500 ));
没有explicit导致的性能陷阱 在性能关键、资源敏感的软件开发中,没有使用explicit,超出预期的隐式转换,可能无意间消耗内存资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Matrix { double * data; size_t size_; public : Matrix (size_t size) : size_ (size) { data = new double [size * size]; } }; void compute (const Matrix& m) compute (1000 );
这时,通过使用 explicit,要求必须明确意图的进行调用,修改上面的代码
1 2 3 4 5 6 7 8 explicit Matrix (size_t size) : size_(size) { data = new double [size * size]; } compute (Matrix (4 ));
这种场景,主要防止的是,有可能开发人员根本没有意识到会触发内存分配,或者误在性能敏感的代码中意外创建大对象。
加上explicit对列表初始化的影响 分析完单参数构造函数非必要最好加上explicit关键字之后,我们再看看,如果多参数构造函数加上explicit,又会有什么影响呢?
官方的说法是:当explicit构造函数接受std::initializer_list时,会失去所有数量的初值的隐式转换能力。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Container {public : Container (std::initializer_list<int > values); }; class SafeContainer {public : explicit SafeContainer (std::initializer_list<int > values) }; Container c1 = {}; Container c2 = {42 }; Container c3 = {1 , 2 , 3 }; SafeContainer sc1 = {}; SafeContainer sc2 = {42 }; SafeContainer sc3 = {1 , 2 , 3 }; SafeContainer sc4{}; SafeContainer sc5{42 }; SafeContainer sc6{1 , 2 , 3 };
加上explicit对多参数构造函数的影响 如果是普通的多参数构造函数加上explicit,又会有什么影响呢?
代码如下:
1 2 3 4 5 6 7 8 9 10 11 class P {public : explicit P (int a, int b, int c) }; P obj1{1 , 2 , 3 }; P obj2 (1 , 2 , 3 ) ; P obj3 = {1 , 2 , 3 }; P obj4 = P{1 , 2 , 3 };
为什么加explicit会影响拷贝初始化呢?
用{1, 2, 3}创建临时对象(需要隐式调用构造函数)
将临时对象拷贝给目标变量explicit阻止了第一步的隐式调用。
有些场景需要加,但是有些场景我们又不应该使用explicit
拷贝和移动构造函数绝对不要加explicit 虽然 C++ 语法上允许你给拷贝/移动构造函数加上 explicit,但在工程实践中,这样做基本等于“自杀”,或者说是给使用者(包括你自己)制造巨大的麻烦。
如果说拷贝和移动构造函数加了explicit,这会发生什么?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 explicit MyClass (const MyClass& other) explicit MyClass (MyClass&& other) MyClass obj1; MyClass obj2 (obj1) ; MyClass obj3 = obj1; void process (MyClass obj) MyClass original; process (original); process (MyClass (original)); std::vector<MyClass> vec; MyClass obj; vec.push_back (obj); MyClass createObject () { MyClass obj; return obj; }
关于拷贝/移动构造函数加explicit会破坏返回值语义,有些小伙伴可能像我一样,在这里会有一个疑问:“C++ 不是有 RVO/NRVO (返回值优化) 吗?编译器不是会把拷贝直接消除掉吗?既然消除了,为什么还要检查构造函数?”
这是因为这里有两步:
语义检查 (Semantic Check):编译器的第一步是检查“如果你要拷贝,代码写得对不对”。这一步要求拷贝/移动构造函数必须是可访问的且非 explicit 的。
代码生成与优化 (Code Generation & Optimization):只有通过了语义检查,编译器才会进行第二步优化(RVO),在运行时消除这次拷贝。
所以,结论就是:即使 RVO 会在运行时消除拷贝,explicit 依然会在编译时导致报错,因为它阻断了语义检查阶段的合法性。
正确的做法
1 2 3 4 5 6 7 8 9 10 class MyClass {public : MyClass (const MyClass& other) = default ; MyClass (MyClass&& other) = default ; MyClass (const MyClass&) = delete ; MyClass (MyClass&&) = delete ; };
总结 explicit 的核心目的是防止意外的类型转换(比如把 int 变成 String)。
但是,拷贝和移动本身就是同一种类型的传递,它们在 C++ 语言层面被设计为一种“自然流动”的操作。阻断这种流动(加上 explicit),就会导致这个类在 C++ 的生态系统中寸步难行。
参考 Google C++ 编程规范的建议,我的使用原则目前是:
(1)原则上,所有的单参数构造函数都应该加上 explicit。除非你真的希望用户使用这种隐式转换带来便利。(例如模拟基础数据类型)
(2)多参数构造函数(C++11 之前通常不需要,但 C++11 引入了列表初始化 {})按具体场景决定加不加explicit:如果构造函数支持列表初始化,且你不想让 {1, 2} 隐式变成你的对象,也要加 explicit。
(3)拷贝/移动构造函数,绝对不要加 explicit。
(大家有什么使用习惯吗?欢迎评论区交流)