刚搭好 Hexo 博客,兴冲冲地在 Google 搜索栏输入 site:catistrue.com,结果却是“找不到任何与此相关的内容或信息”。

那种心情,大概就像是新开了一家店,装修得漂漂亮亮,结果门口连个路牌都没有,谁也找不到。
今天记录一下我为了让 Google 收录我的博客,踩过的坑和最终的解决方案。
如果你也像我之前一样发出新手疑问,这篇文章应该能帮到你。
核心误区:建好站 = 能被搜到?
这是最大的误区。网站上线 ≠ 被收录。
互联网就像一个巨大的图书馆,Google 是图书管理员。我们建好博客,只是把书写好了放在自家书房里。如果不主动去“登记”,图书管理员是不知道你这本书存在的。
所以,我们需要做两件事:
- 验明正身:告诉 Google 这个域名是我的(GSC 验证)。
- 提交目录:把书的目录交给 Google(提交 Sitemap)。
第一步:注册 Google Search Console (GSC):
Google Search Console (GSC) 是 Google 官方的站长工具。验证所有权最推荐的方法是 DNS 验证。
(1) 输入你的域名 catistrue.com (选左边的“网域”/Domain)。
(2) 验证所有权:它会给你一段 TXT 代码。(复制下来就行)
(3) 去你的服务商(比如我是去 腾讯云 DNSPod),添加一条 TXT 记录,把代码贴进去。
第二步:GSC 验证
Google 只是想验证你拥有 catistrue.com 这个根域名。所以在腾讯云 DNSPod新增这样一个记录:
主机记录:请写 @ (或者留空不填,但在 DNSPod 里通常填 @ 代表根域名)。
记录类型:TXT
记录值:google-site-verification=… (刚才复制下来的 TXT 代码)
这里我遇到了一个新手常犯的犹豫:我已经有一条 @ 的 A 记录指向服务器 IP 了,再加一条 @ 的 TXT 记录用来验证,会冲突吗?
答案是:完全不会。
- A 记录:负责指路,告诉浏览器网站在哪里。
- TXT 记录:负责备注,告诉 Google 验证码是什么。
只要类型不同(一个是 A,一个是 TXT),它们就能和平共处。
所以放心添加即可。
第三步:最关键的 Sitemap
验证通过只是拿到了“房产证”,想让爬虫快速抓取,必须主动提交 Sitemap(站点地图)。
1. 检查 Hexo 是否有 Sitemap
访问 https://www.catistrue.com/sitemap.xml,如果 404,说明没装插件。
这里插播一段,如果像我之前一样通过CI/CD部署的,就可以感受到它的优势。
比如一般来说,直接通过安装本地环境搭建Hexo+GitHub的,需要在博客根目录运行:
1 | npm install hexo-generator-sitemap --save |
然后重新 hexo g -d 部署。再次访问,看到一堆密密麻麻的代码(XML 格式),就说明成功了。
但是,如果走CI/CD部署的,即使手边这台电脑没有配置Node.js环境,没有配置docker环境,仍然可以很轻松给项目添加新插件。这是一个非常现实的场景。而且其实非常简单,甚至比有 Docker 还简单。
核心逻辑是: 你只需要修改“购物清单” (package.json),然后把清单传给 GitHub。真正负责“买菜做饭” (安装插件、生成页面、部署) 的是 GitHub Actions,而不是你的本地电脑。
你完全不需要在本地运行 npm install 或 hexo g -d。
操作步骤 (如果已经安装过hexo-generator-sitemap插件可跳过这段)
对于我们这种CI/CD部署的场景,你只需要直接编辑文件即可:
(1)手动修改 package.json
在你的项目根目录下,找到 package.json 文件。这是 Node.js 项目的依赖清单。
找到 "dependencies" 部分,手动添加一行:
1 | "dependencies": { |
(注意:上一行的末尾别忘了加逗号 ,,json 格式很严格)
(2)配置 _config.yml (如果需要)
通常 sitemap 插件安装后会自动生效,但为了稳妥,我们可以在 _config.yml 里开启它。
打开根目录的 _config.yml,在末尾添加:
1 | # Sitemap |
(3)提交代码
这就是最后一步了。我只需要把这两个文件的修改 Push 到 GitHub。
1 | git add package.json _config.yml |
(4)见证奇迹
- 代码推送到 GitHub 后,GitHub Actions 会自动触发。
- Action 在云端运行时的逻辑是:
npm install。 - 这时候,它会读取我刚才修改过的
package.json,发现:“咦,多了一个hexo-generator-sitemap!” - 于是它会自动下载安装这个插件。
- 接着执行
hexo generate时,插件就会生效,生成sitemap.xml。 - 最后部署上线。
总结
你不需要在本地安装 Node.js,也不需要运行 npm 命令。
只要修改 package.json 这个纯文本文件,你就相当于指挥了云端的服务器帮你安装了插件。
这就是 CI/CD (持续集成/持续部署) 的最大优势!
2. 提交给 GSC
在 GSC 后台找到“站点地图”,输入 https://www.catistrue.com/sitemap.xml 提交。

到这一步提交之后,就是等待啦。
第三步:等待
提交完 Sitemap,最搞心态的一幕出现了:状态栏显示红色的 **“无法抓取” (Couldn’t fetch)**。
当时我也慌了,以为是 Sitemap 格式错了,或者是 Vercel 屏蔽了爬虫。
真相是:这是 Google 的服务器延迟/抽风。
千万别慌,不用做任何修改。
如果你的 https://www.catistrue.com/sitemap.xml 能用浏览器打开,那就绝对没问题。
恭喜你,操作步骤已经全部完成!
为什么会显示“无法抓取”?
- Pending 状态:虽然它说“无法抓取”,但实际上 Google 内部的意思往往是“pending(排队中)”。你的请求已经提交上去了,但服务器还没来得及去真的访问。
- CDN 延迟:你的网站在 Vercel 上,DNS 解析有时候会有微小的延迟,导致 Google 爬虫第一下没连上。
现在我们该做什么?
什么都不用做,关掉页面去睡觉:P
真的,这是解决这个红字最好的办法。
- 不要 删除它重新提交(这会让排队重置)。
- 不要 怀疑你的 sitemap 有问题(只要你能用浏览器打开,它就是没问题的)。
大概过了1个多小时,我再回来刷新这个页面,这个红色的“无法抓取”就会神奇地变成绿色的“成功”,或者显示出“已发现的网址数”。
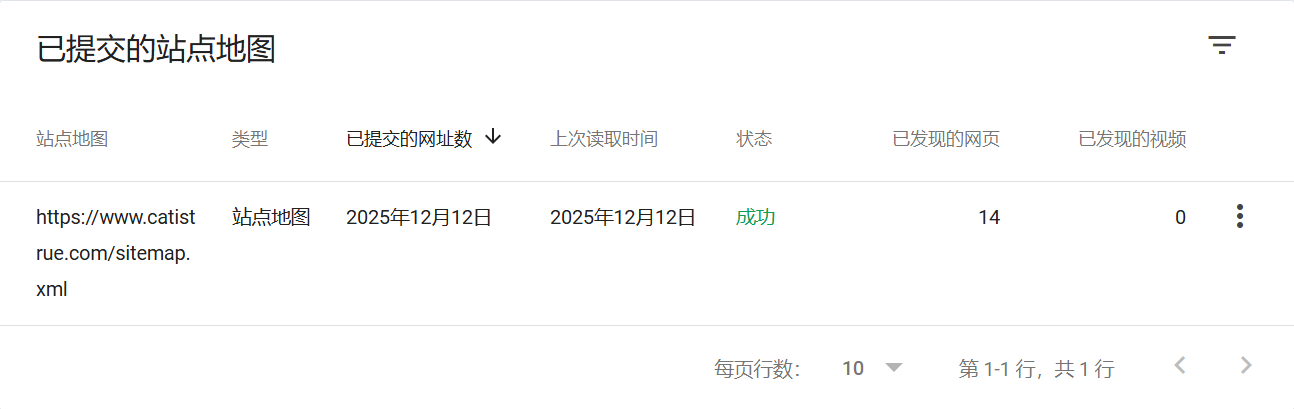
成功了以后,为什么我在google上搜索site:catistrue.com还是没有内容呢
这是非常正常的,千万别焦虑!
你现在的状态就像是:刚刚把店铺的传单(Sitemap)发给了路过的推销员(Google),但他还没来得及把你的店名印到黄页(搜索结果)上。
从“提交成功”到“搜得到”,中间还有一段 “收录期”,通常需要 数天到两周 的时间。
为什么会这样?Google 正在后台忙这三件事:
- 发现(Discovery):你刚提交了 Sitemap,Google 知道了“哦,这里有个新网站
catistrue.com”。 - 抓取(Crawling):Google 会派出爬虫(Googlebot)顺着你的 Sitemap 链接,真正地去访问你的每一个网页,下载内容。
- 索引(Indexing):爬虫把内容带回去,Google 的算法要分析你的文章质量、关键词,确定没有违规内容后,才会把它放进巨大的数据库里。
只有完成了第 3 步,你在 Google 搜 site:catistrue.com 才会出现结果。
你现在怎么确认 Google 到底在干活没?
虽然搜不到,但你可以用 Google Search Console 里的一个强力工具来查看进度:
- 在 Search Console 顶部,有一个长长的搜索框(写着“检查 catistrue.com 中的任何网址”)。
- 把你的首页地址
https://catistrue.com/粘贴进去,回车。 - 系统会跑一会儿,然后给你一个报告:
- 如果显示 “网址不在 Google 服务中”:说明爬虫还没来,或者还没处理完。(正常,继续等)
- 你可以点击灰色的按钮 “请求编入索引”。这相当于给爬虫插个队,告诉它:“哥们,这里我很急,优先来看一下。”
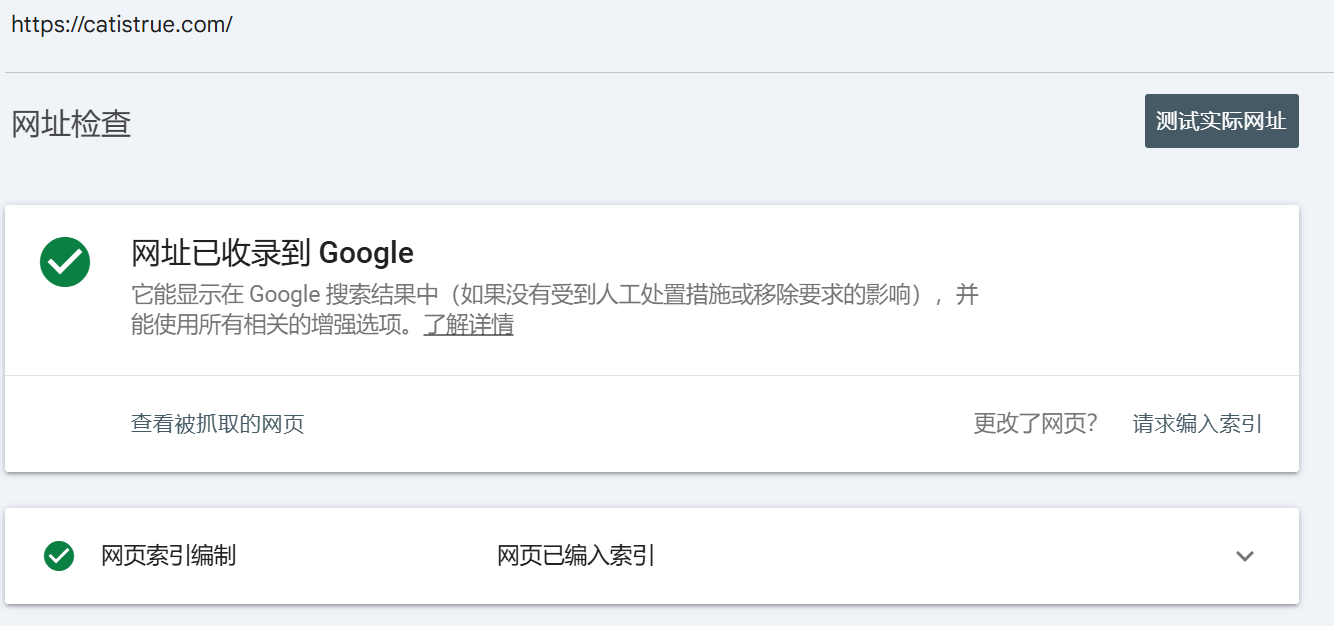
当出现收录成功后,现在的状态:
你的网站已经“拿到户口本”了!
现在你可以放一百个心,不需要再做任何 SEO 的技术配置了。你现在唯一的任务就是:写好博客,发布出去!
总结:从提交到收录的等待期
- 不要慌:新站通常需要 3天 - 1周 才能在搜索结果里冒头。
- 不要改:确保你的配置是正确的,千万别因为搜不到就去乱改 DNS 或 Sitemap。
- 去写文章:趁这段时间多写一两篇高质量文章,Google 爬虫第一次来如果发现内容很丰富,会对你的网站印象更好,以后收录会更快!
在此期间,我们可以使用 GSC 顶部的搜索框“检查网址”,手动点击 “请求编入索引” 来给爬虫插个队。
剩下的,就是保持更新,静待花开。希望大家的博客都能早日出现在搜索结果的第一位!
