Qt多语言处理
环境
利用Qt原生模块
tr函数引入
1 | QString text=tr("Measure"); |
语言模块
通过Qt Command Prompt
(1)命令行执行生成ts文件
1 | lupdate yourProject.pro -ts translations/zh_CN.ts |
(2)手动修改ts文件的中文翻译
(3)生成qm文件
1 | lrelease translations\zh_CN.ts -qm translations\zh_CN.qm |
在本地配置了多个 Git 账号(使用 SSH Key 管理)的情况下,从 GitLab 拉取三个仓库的代码。
git pull 正常,直接走 SSH 验证。git pull 失败,提示需要输入密码 (Enter password)。通过查看远程仓库地址发现差异:
正常的仓库 (A/B):
使用域名连接:
1 | git remote -v |
异常的仓库 (C):
使用 IP 地址连接:
1 | git remote -v |
本地的 SSH 配置文件 (~/.ssh/config) 是基于域名 (Host) 来匹配私钥的。配置通常如下所示:
1 | # ~/.ssh/config 示例 |
gitlab.namexxx.com 时,SSH 代理能成功匹配到 id_rsa_work 私钥。10.10.10.xxx 时,SSH 代理无法将这个 IP 匹配到上述规则,导致找不到对应的私钥。将异常仓库的远程地址从 IP 修改为 域名。
执行命令:
1 | # 1. 进入项目目录 |
在多 Git 账号环境下,必须严格保证 Remote URL 的 Host 部分与 ~/.ssh/config 中的 Host 定义一致。不要混用 IP 地址和域名,否则 SSH 规则将失效。
在 C++ 开发中,std::vector 是最常用的容器,但它也是很多“诡异”崩溃的源头。最近在排查一个 MSVC Debug 模式下的崩溃时,遇到了一个经典的 迭代器失效(Iterator Invalidation) 问题。
最令人困惑的是:旧代码里已经提前 reserve 了足够的空间,理论上没有发生内存重新分配(Reallocation),为什么迭代器还是失效了?
这段旧代码逻辑大致如下:我们需要反向遍历一个 vector,找到符合条件的元素后,向 vector 尾部添加一个新元素,然后继续使用当前的迭代器处理数据。
1 | // 伪代码示例 |
这段旧代码在linux下运行了上十年。
但是,在跨平台移植到windows上后,在 Visual Studio Debug 模式下,运行到 process(*it) 时直接弹窗崩溃:
Debug Assertion Failed!
Expression: can’t decrement invalidated vector iterator
翻译过来就是:“无法对一个已经失效的 vector 迭代器进行减法操作(–)”。
很多开发者的第一反应是:“可能是 push_back 导致 vector 扩容了,旧内存被释放,所以迭代器失效。”
但是翻看项目代码发现,旧代码里有 blocks.reserve(1000),已经确保 capacity 远大于 size(崩溃时是size值是8)。但结果依然崩溃。为什么?
这是最大的误区。虽然内存重分配(Reallocation)一定会导致所有迭代器失效,但即使不发生内存重分配,某些操作依然会让迭代器失效。
根据 C++ 标准:
如果
push_back没有导致内存重分配,那么end()迭代器以及所有指向尾后位置的迭代器都会失效。如果重新
reserve(),那么所有迭代器可能失效
崩溃的核心原因在于代码里使用了 rbegin() / rend()。
在 C++ STL 中,反向迭代器std::reverse_iterator本质上是正向迭代器的包装器,其内部实现依赖于end()位置:
rbegin() 在物理上对应的是 end() - 1。rend() 在物理上对应的是 begin() - 1(虚拟位置)。所以当我们执行 push_back 时:
reserve(1000),当前size是8,所以没有触发内存重新分配)。vector 的 end() 位置改变了(因为多了一个元素,尾巴向后移了一位)。由于反向迭代器依赖于 end() 的相对位置,一旦 end() 发生改变,所有基于旧 end() 建立的反向迭代器关系在逻辑上就“错位”了。
所有依赖end()的反向迭代器立即失效
即使内存未重分配,迭代器仍被标记为无效
在 Release 模式下,这行代码可能侥幸能跑通(这叫未定义行为,Undefined Behavior),因为内存确实没动。但这是未定义行为(UB),随时可能崩溃或产生错误结果。
但在 Debug 模式下,MSVC 的 STL 实现开启了 Iterator Debugging。它维护了一个迭代器版本列表:
it 时,它记录了 vector 的当前版本。push_back 时,vector 的版本号更新了。*it 时,调试器发现 it 的版本号过期失效了,直接断言崩溃,抛出 can't decrement invalidated vector iterator。这是一种保护机制,提醒你:这段代码逻辑在标准层面上是错误的。
既然知道了原因,解决起来就很容易了。核心原则是:永远不要相信修改容器后的旧迭代器。
这是最安全、改动最小的方法。在调用 push_back 之前,把我们需要的数据拷贝一份出来。
1 | for (auto it = blocks.rbegin(); it != blocks.rend(); ++it) { |
下标(Index)不依赖于迭代器对象,只要不发生内存搬迁(或者你知道搬迁后的新位置),下标永远是数学上的绝对偏移量。
索引不受容器修改影响
1 | // 使用 int 索引代替迭代器 |
1 | graph LR |
reserve()仅影响capacitypush_back()修改sizesize变化有关,与capacity无关reserve 不能防止迭代器失效:它只能防止内存重分配,但 push_back 依然会改变容器的逻辑状态(如 end() 位置)。vector 的过程中,一旦执行了 push_back、insert 或 erase,请默认当前所有的迭代器都已失效。invalidated vector iterator 报错是在预警,避免将隐患带入生产环境。迭代器失效是C++中最常见的陷阱之一,特别是在使用容器反向迭代时。
在修改容器之前保存数据,而不是依赖迭代器,养成良好的安全编程习惯,可以避免许多难以调试的运行时错误。
“在C++中,容器和迭代器的关系就像舞伴——其中一方改变动作时,另一方必须重新协调步伐,否则就会踩到对方的脚。”
本文由排查真实 Bug 总结而来,希望能帮你少踩一个坑。
之前一直在linux下,跨平台移植到windows下的时候发现命令怎么用都不顺手,整理一下常用的命令:对目录/文件的常用增、删、重命名、复制、移动、路径切换命令记录。
由于 Windows 有两个主要的命令行环境:CMD (命令提示符) 和 PowerShell(Git Bash 兼容部分 Linux 命令),它们的指令略有不同。
下面以 PowerShell 为例(Git Cmd 也通用)。
删除前最好确认路径,
/s会把子目录也删掉,/q静默,不再确认。
1 | rd /s /q 目录名 |
1 | del /f /q 文件名 REM /f 强制删除,/q 静默 |
1 | copy 源文件 目标文件或目录 |
推荐用 robocopy。
1 | robocopy 源目录 目标目录 /e REM /e 递归复制所有子目录,包括空的子目录。 |
1 | move 源文件 目标文件或目录 |
1 | move 源目录 目标目录 |
1 | C: |
1 | cd 路径 |
cd /d可以 同时 切换盘符和目录,比较方便。
1 | cd \ |
1 | mkdir 目录名 |
cmd 里没有专门的“新建空文件”命令,一般用下面几种方式:
1 | type nul > 文件名 |
code 文件名创建空文件并打开1 | ren 原目录名 新目录名 |
1 | ren 原文件名 新文件名 |
删除目录的指令和linux完全不一样,rd /s /q 目录名
删除文件的指令也很奇怪,del /f /q 文件名
windows下复制文件是copy 源文件 目标文件或目录
复制目录更费劲,是robocopy 源目录 目标目录 /e
移动文件或目录都是move 源 目标指令
创建目录mkdir,还好,这个和linux一致(终于有一个一样的了)
创建文件是type,如果安装了vscode ,可以直接用code 文件名创建空文件并打开
重命名文件或目录都是ren 原名 新名指令
两个平台的指令差异还挺大。。
在 C++ 单元测试的世界里,一直流传着一个“邪道”技巧。
当你面对一个庞大的遗留类,想要测试其中一个复杂的 private 辅助函数,或者验证某个 private 成员变量的状态,但又不想(或不能)修改原始头文件去添加 friend 声明时,很多人的第一反应是使用那个著名的“黑魔法”:
1 |
这个技巧的核心逻辑非常简单粗暴:预处理器的宏替换。
C++ 的编译过程是分阶段的。在编译器真正开始语法分析之前,预处理器会先处理所有的 #include 和 #define。
当我们写下:
1 | // Test.cpp |
预处理器在展开 MyLegacyClass.h 时,会将其中的所有 private 关键字替换为 public。
对于编译器来说,在编译 Test.cpp 这个单元时,MyLegacyClass 的所有成员确实就是公有的。因此,测试代码可以直接调用 MyLegacyClass::PrivateFunc() 而不会报“访问权限错误”。
这是编译期的欺骗,很完美,对吧?
在 Linux 环境下,GCC 和 Clang 遵循 Itanium C++ ABI(应用程序二进制接口)标准。
在该标准下,函数的符号修饰(Name Mangling)主要包含函数名、命名空间和参数类型等信息,但通常不包含访问控制级别(public/private/protected)。
也就是说,对于下面这个函数:
1 | class MyLegacyClass { |
无论它是 private 还是 public,GCC 生成的符号名可能都是类似 _ZN7Scanner11UpdateTokenEi 的样子。
MyLegacyClass.cpp 正常编译,PrivateFunc 是 private,生成符号 _ZN7Scanner11UpdateTokenEi。Test.cpp 用了黑魔法,编译器以为 PrivateFunc 是 public,生成调用指令,寻找符号 _ZN7Scanner11UpdateTokenEi。在实践中,Itanium ABI 往往能“宽容”地让它跑通。因此,这一招在 Linux 环境下(使用 GCC 或 Clang)屡试不爽,属于“快速通关”的秘籍。
不过,需要注意的是,当你试图将代码移植到 Windows 环境,使用 Visual Studio (MSVC) 编译时,黑魔法就会失效——**链接错误 (LNK2019)**。
如果在 Windows 上使用 MSVC 编译器做同样的事情,你会收到类似这样的错误:
error LNK2019: 无法解析的外部符号 “public: bool __cdecl MyLegacyClass::PrivateFunc(int)” (?PrivateFunc@MyLegacyClass@@QEAAXH@Z),函数 “private: virtual void __cdecl ATest_APrivateFuncCase_Test::TestBody(void)”(?TestBody@ATest_APrivateFuncCase_Test@@EEAAXXZ) 中引用了该符号
这表明你使用 #define private public 这种“黑魔法”虽然欺骗了编译器(Compiler),让你在测试代码中可以调用私有函数,但它改变不了链接器(Linker)的事实。
微软的 C++ ABI 与 Itanium ABI 不同。MSVC 在生成函数的修饰名(Mangled Name)时,将函数的访问控制权限(Access Specifier)编码进了符号名里。
我们来看一下区别:
| 代码定义 | 访问权限 | MSVC 生成的符号名 (大致示意) |
|---|---|---|
void PrivateFunc(int) |
private | ?PrivateFunc@MyLegacyClass@@AEAAXH@Z |
void PrivateFunc(int) |
public | ?PrivateFunc@MyLegacyClass@@QEAAXH@Z |
我们注意到:
A (AEAA...)Q (QEAA...)**源文件编译 (MyLegacyClass.cpp)**:
你编译项目源代码时,没有加黑魔法。编译器看到的是 private,生成的 MyLegacyClass.obj 里,函数的符号是 **带 A 的 (Private 版)**。
测试文件编译 (Test.cpp):
你使用了 #define private public。编译器被欺骗了,它认为 PrivateFunc 是 public 的。于是它在生成 Test.obj 时,生成了一个寻找 带 Q 的 (Public 版) 符号的指令。
链接阶段:
链接器开始工作。测试代码大喊:“给我一个 ...QEAA... (Public) 的函数!”
由于只有 MyLegacyClass.obj,它回答:“我只有 ...AEAA... (Private) 的版本。”
链接器:不匹配,报错,LNK2019。
这就是为什么MSVC下加了黑魔法,却仍然死活链接不上的原因。
一般来说,我们 #define private public 是未定义行为且在 Windows 上不可用,我们应该如何测试私有成员呢?
FRIEND_TEST (推荐)这是最标准、最安全的方法。它利用了 C++ 的 friend 机制,专门为测试开放白名单。
在头文件中:
1 |
|
在测试文件中:
1 | TEST(ATest, APrivateFuncCase) { |
这种方式生成的符号名是完全一致的,无论在 Linux 还是 Windows 都能完美运行。
如果你的私有逻辑非常复杂以至于需要大量测试,这通常意味着该逻辑应该被提取到一个独立的类中(Impl 类)。你可以将这个 Impl 类设为 public(或在内部头文件中定义),然后单独对其进行测试。
#define private public 就像是程序员的禁术。它在 Linux/GCC 的宽容下或许能让你尝到甜头,但在 Windows/MSVC 严谨的 ABI 规则面前,它会罢工报警。
还是权衡一下使用场景再决定要不要用吧。
刚搭好 Hexo 博客,兴冲冲地在 Google 搜索栏输入 site:catistrue.com,结果却是“找不到任何与此相关的内容或信息”。

那种心情,大概就像是新开了一家店,装修得漂漂亮亮,结果门口连个路牌都没有,谁也找不到。
今天记录一下我为了让 Google 收录我的博客,踩过的坑和最终的解决方案。
如果你也像我之前一样发出新手疑问,这篇文章应该能帮到你。
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
1 | $ hexo new "My New Post" |
More info: Writing
1 | $ hexo server |
More info: Server
1 | $ hexo generate |
More info: Generating
1 | $ hexo deploy |
More info: Deployment
终于拥有了自己的独立域名博客!🎉
这篇博客记录了我从零开始搭建 catistrue.com 的全过程。
在这场折腾中,我本来想直接用Hexo+GitHub Page方案。但是考虑到我有多台电脑,有时候会随机打开某一台开始工作,难道我要每一台都配置Node.js等等各种环境?
经过我的研究,对于我这种情况,最完美的方案是采用 “本地 Docker 预览 + GitHub Actions 自动构建 + 阿里云加速镜像” 的架构。
这个时候,我的核心思路:CI/CD 自动化流
不要在任何一台电脑上执行 hexo d(部署命令)。所有的部署工作都交给云端自动化完成。
多台电脑:只负责写 Markdown 文章,然后 git push。
GitHub:负责存储源码,并通过 GitHub Actions 自动生成静态页面。
阿里云:作为国内访问的“加速节点”或“镜像站”。
为了保证我在任何一台电脑上都能无缝切换,同时利用阿里云加速,我开始按照 “本地环境 -> 代码仓库 -> 自动化构建 -> 双路部署” 的顺序来搭建。
目标: 在我顺手打开的这台电脑上,用 Docker 初始化 Hexo,并建立 Git 仓库。
我的电脑上已经安装了:
打开终端(Windows 下建议用 PowerShell 或 Git Bash),进入我想存放博客的目录:
1 | # 1. 创建博客目录 |
在 my-blog 根目录下创建一个 docker-compose.yml 文件。这是你多台电脑同步的核心:
1 | version: '3' |
在终端运行:
1 | docker-compose up |
访问 http://localhost:4000。如果看到 Hexo 的默认页面,说明本地环境搭建成功。按 Ctrl+C 停止。
目标: 将源码上传,并让 GitHub Actions 接管构建任务。
你的用户名.github.io (要设置为Public,我一开始设置为私有仓库,结果发现免费账号无法直接在私有仓库中使用 GitHub Pages)。在 my-blog 目录下:
1 | # 生成 .gitignore (Hexo 初始化时通常已有,确认包含 node_modules, public, db.json) |
在项目根目录创建路径 .github/workflows/deploy.yml,填入以下内容。
注意:此时我们先只配置 GitHub Pages,确保跑通后再加阿里云/腾讯云。
1 | name: Deploy Blog |
提交这个文件并 Push。
去 GitHub 仓库的 Actions 标签页,查看是否构建成功。

为了看更详细的失败原因,可以去 GitHub 仓库的 Actions 标签页,点击那个红色的失败任务,点击左侧的 build。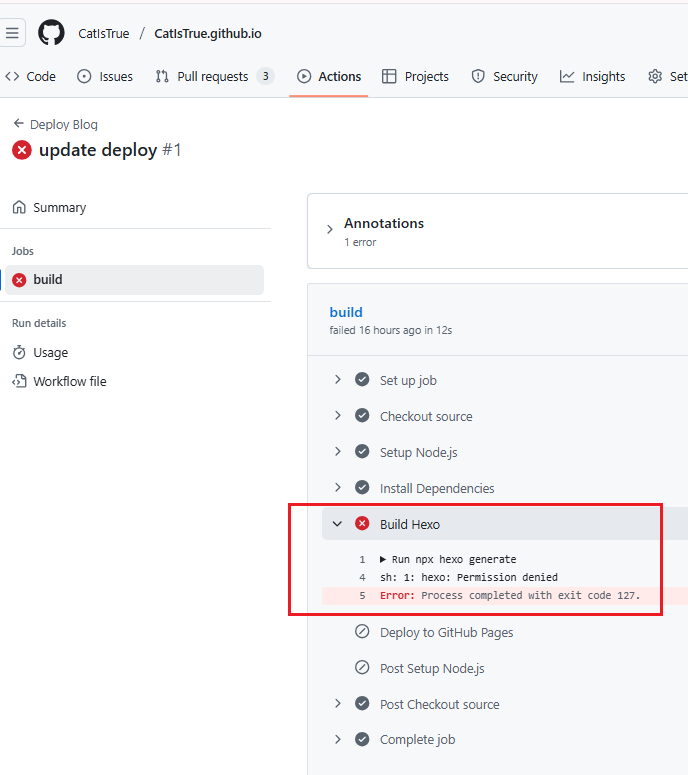
网上查了一下这个报错 sh: 1: hexo: Permission denied 结合 Exit code 127,发现是因为把 Windows 下生成的 node_modules 文件夹上传到 GitHub 了。
node_modules。node_modules 里的 hexo 命令时,发现文件权限不对,或者格式不对,于是报“拒绝访问”。如果你也遇到了一样的问题,解决方法也很简单,只需要从 Git 仓库中删除 node_modules,并让 GitHub Actions 自己重新下载安装。
打开本地电脑的终端,进入博客目录,依次执行以下命令:
(1)第一步:修改 .gitignore
确保你的目录里有一个 .gitignore 文件。
如果没有,新建一个;如果有,确保里面包含 node_modules。
可以使用命令追加:
1 | # Windows PowerShell 下追加内容(如果文件不存在会自动创建) |
(2)第二步:从 Git 记录中删除这些文件
这一步很重要,不要直接在文件管理器删文件夹,我们要的是从“Git 的追踪记录”里删除,但保留你本地的文件。
1 | # 1. 从 Git 暂存区删除 node_modules (不会删除你本地的实体文件) |
(3)第三步:去 GitHub Actions 查看
当你执行完 git push 后,GitHub Actions 会自动触发一次新的构建。
这次,它在 Install Dependencies 这一步会下载全新的、适配 Linux 环境的依赖包,hexo generate 就不会报错了。
成功后,可以去仓库 Settings -> Pages,将 source 改为 gh-pages 分支。
此时我的博客已经可以通过 https://catistrue.github.io/ 访问了。
鉴于我的具体需求: “个人博客 + Docker 部署 + 需要国内访问加速” ,到底是选择腾讯云还是阿里云,我纠结了一下。经过我翻看各大网友的建议,作为个人博主,我最后决定选择腾讯云,它够轻量也够用了,省下来的钱和带宽,对个人博客来说才是实打实的。
而且,我可以通过 腾讯云 DNS + Vercel ,个人版够用。
于是,我现在的架构是 “基于 Serverless 的现代化博客架构:本地 Hexo + Git 版本控制 + Vercel 边缘网络自动部署 + 腾讯云 DNS 解析” (据说是全球最流行的 JAMstack 架构,在技术圈里是非常时髦的!)(这个说法我还没有考证过,欢迎各位小伙伴解答。)
整个过程大概需要 15-20 分钟,主要时间花在“实名认证”的审核上。
进入域名注册页面:
https://dnspod.cloud.tencent.com/搜索心仪的域名:
CatIsTrue)。选择与购买:
.com**(最通用、看着专业),如果为了便宜也可以选 .cn(必须实名且有些限制),或者 .net。.com就够了,不用看它绑定的一堆组合(省杯咖啡钱)填写域名信息模板(关键步骤):
隐私保护(重要!):
支付:
验证隐私保护设置是否开启成功(保护隐私比较重要)
搞定域名后告一段落!
但如果现在要访问 http://catistrue.com/ 会发现还是打不开。
这是完全正常的!别慌。
买完域名到能正常访问,中间缺了最关键的搭桥环节。
我们在腾讯云买了 catistrue.com,这就像刚领了个车牌号。但是:
现在的空白,说明这个域名还不知道该去哪里。
在解决这个问题前,先插播一段:我需要配置Vercel
因为我不想在接下来换电脑的时候反复配环境,我的预期是新的电脑只写文章 (CI/CD 自动化)利用 GitHub Actions,把“生成网页”这个苦力活交给 GitHub 的服务器去做。并且希望 国内外都能访问,所以我最后采用 “GitHub 存储代码 + Vercel 自动构建/托管” 的组合。
为什么要这样组合?
.md 文件,Vercel 就会立刻感知到,自动在云端帮你执行 hexo g 生成网页并发布。你连 GitHub Actions 脚本都不用写!下面是全流程的操作步骤
Hexo。hexo generate (或者 hexo g)。public。等几十秒,你会看到满屏庆祝的彩带,说明 Vercel 已经成功把你的博客在云端构建出来了!
这一步就是把刚才我们在腾讯云买的域名,指引到 Vercel 上。
在 Vercel 端设置:
进入你刚才创建的项目 -> Settings -> Domains。
输入框:
填好 catistrue.com (刚才在腾讯云注册的域名)
**Redirect catistrue.com to www.catistrue.com (Recommended)**:
务必勾选(默认已经勾选了)!
catistrue.com (根域名) 和 www.catistrue.com (带www的域名)。catistrue.com 时,会自动跳转到 www.catistrue.com。这对 SEO(搜索引擎优化)和 CDN 缓存都更友好。如果不勾选,两个域名是独立的,虽然也能访问,但不够规范。接着直接点击右下角的黑底白字按钮 “Add” (或者 “Save”) 即可!
点完之后,它会跳回原来的界面,并显示两个红色的或者黄色的提示(Invalid Configuration),这是正常的,因为你还没去腾讯云(DNSPod)那边改解析记录。(戳开这俩提示,可以看到对应的@、www信息,后续要用)
回到腾讯云
请务必完全按照 Vercel提供的信息填写,不要自己发挥:
第一条记录:给根域名 catistrue.com 用的
@Axx.xx.xx.xx (以 Vercel 显示的为准)第二条记录:给 www 子域名用的
wwwCNAMExxx.com (以 Vercel 显示的为准)操作完毕后
回到 Vercel 这个界面,等待几分钟(有时候秒级生效,有时候要等10分钟)。
那个红色的 Invalid Configuration 会自动变成蓝色的 Valid 或者对勾。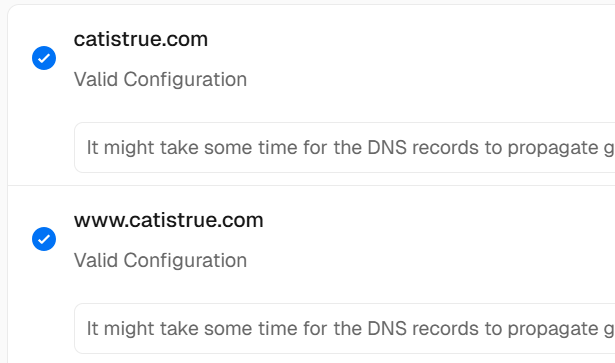
为了防止 Hexo 在生成的时候不知道自己的域名变了,建议修改你本地博客的配置文件。
_config.yml 文件。url: 这一行。url: https://catistrue.com激动人心的时刻来了,现在,打开电脑,除了可以访问https://catistrue.github.io/ ,还可以访问https://catistrue.com , https://www.catistrue.com。
个人博客网站可以打开啦!(太棒了!🎉 恭喜我们!)
ps
如果到这一步还是能打开个人网站,不用担心,现在打不开,只剩下一个原因:SSL 证书还没颁发好,或者本地 DNS 缓存没更新。可以再等一会儿,或者在终端输入ipconfig /flushdns刷新一下DNS解析缓存看看。
恭喜!我们已经完成全部的搭建过程了。
以后的工作流:
xxx.md 文章。source/_posts 文件夹。catistrue.com 上就有新文章了。访问体验:
如果你也想拥有一个酷炫的独立博客,希望这篇教程能帮到你。
checkout 分支歧义问题在日常开发中,我们通常只需要面对一个远程仓库(origin)。但有时候,为了同步代码或迁移仓库,我们会在本地配置多个 Remote(例如同时存在 origin 和 gitlab)。
最近遇到了一个有趣的报错:明明远程有这个分支,但我执行 git checkout 时却失败了。
这篇文章记录了原因和解决方法。
假设我在终端执行以下命令,想切换到一个老分支:
1 | git checkout v3.0_old |
Git 报错或者提示找不到该分支(尽管我知道远程肯定有)。
经过检查 git remote -v 和 git branch -r,我发现我的本地仓库配置了两个远程源:

gitlaborigin而且,这两个远程仓库里都有一个同名的分支:
gitlab/v3.0_oldorigin/v3.0_old当我输入简短的 git checkout v3.0_old 时,Git 的内部逻辑是这样的:
v3.0_old 的分支? -> 结果:没有。gitlab 里找到了一个,在 origin 里也找到了一个。简单来说,就是目标不唯一,Git 犯了选择困难症。
解决方法非常简单:显式地告诉 Git,你想用哪一个远程仓库的分支作为“基准”。
通用公式如下:
1 | git checkout -b <本地新分支名> <远程仓库名>/<远程分支名> |
origin如果你主要向 origin 提交代码,或者它是主仓库:
1 | git checkout -b v3.0_old origin/v3.0_old |
这条命令的意思是:在本地新建一个叫 v3.0_old 的分支,并让它明确追踪 origin 下的对应分支。
gitlab如果你更倾向于使用 gitlab 这个源:
1 | git checkout -b v3.0_old gitlab/v3.0_old |
当你的 Git 环境中存在多个 Remote 时,偷懒使用 git checkout <branch_name> 可能会失效。
建议养成习惯,在多 Remote 环境下,使用 git checkout -b ... origin/... 这种显式指定上游的写法,可以避免很多不必要的混淆。
有时候,需要在一个电脑上管理多个 Git 账号(比如一个是 GitLab,一个是 GitHub,或者两个都是 GitHub 账号)是一个比较常见的场景。
如果不配置好,很容易出现“用错账号提交代码”或者“没权限推送代码”的尴尬情况。
最优雅、最推荐的方案是使用 SSH Config + 文件夹别名 的方式。
下面是手把手的配置指南:
~/.ssh/config 文件,让 SSH 知道访问不同主机时用哪把钥匙。打开终端(Terminal 或 Git Bash),分别生成两个 SSH Key。
注意要给文件起不同的名字!
1 | # 1. 生成账号1的 Key (假设是 GitHub) |
(如果系统不支持 ed25519,可以用 -t rsa -b 4096 代替)
现在你的 ~/.ssh/ 目录下应该有 4 个文件(两个私钥无后缀,两个公钥带 .pub)。
id_ed25519_gmail.pub 的内容 -> 去 GitHub -> Settings -> SSH and GPG keys -> New SSH key。id_ed25519_163.pub 的内容 -> 去 GitLab -> Settings -> SSH Keys。在 ~/.ssh/ 目录下创建一个名为 config 的文件(如果没有的话)。
1 | # 创建或编辑 config 文件 |
将以下内容填入文件中:
1 | # --- 账号1 (GitHub) --- |
注意: 如果两个账号都是 GitHub,你需要给第二个 Host 起个别名,比如
Host github-123,下面的HostName依然填github.com。
一种方法是你每次 clone 下来后手动设置 git config user.name,不过这很容易忘掉这个步骤。
另一种方法就是接下来,我们可以利用 Git 的 “includeIf” 功能,根据文件夹路径自动切换配置。
规划文件夹:
~/Code/GMail (放项目1)~/Code/Mail163 (放项目2)创建特定的 .gitconfig 文件:
~/.gitconfig-gmail,内容如下:1 | [user] |
~/.gitconfig-123,内容如下:1 | [user] |
**修改主配置文件 ~/.gitconfig**:
打开全局的 ~/.gitconfig,在最下面加入:
1 | # 如果路径包含 ~/Code/GMail/,就引用配置1 |
测试连接:
1 | ssh -T git@github.com |
平时使用:
git clone git@github.com:user/repo.gitgitlab-123),clone 的时候要稍微改一下地址:git clone git@gitlab-123:group/project.git这样配置后,只要你在 ~/Code/GMail 目录下操作,提交记录自动就是邮箱1;在 ~/Code/Mail163 下操作,自动就是邮箱2。完美兼容!